Advertisement
When training a machine learning model, we need a way to measure how well it’s performing. This is where loss functions come in. A loss function gives a number that represents how far off the model’s predictions are from the actual results. The lower this number, the better the model is doing.
Without this feedback, there’s no way for the algorithm to adjust and improve. Loss functions play a quiet but central role in teaching a model what “good” predictions look like. They guide learning in everything from simple regression tasks to deep neural networks.
A loss function is the tool that tells a machine learning model how wrong it is. It takes the model’s prediction, compares it to the actual result, and spits out a single number — the loss. This number represents the cost of the mistake. During training, the model’s entire goal is to adjust itself to make this loss as small as possible.
Imagine a model predicting house prices. If it predicts $300,000 for a house that actually sells for $350,000, it's off by $50,000. The loss function turns that difference into a clear score that the model can work with. By running through thousands or even millions of examples, the model slowly learns which adjustments shrink the loss and which don't. A lower loss means predictions that are closer to reality.
Loss functions often get confused with evaluation metrics like accuracy or F1 score. But there’s a key difference — metrics measure performance after training, while loss functions guide the learning itself during training.
Different problems require different ways to measure error. That’s why there are many types of loss functions designed for different kinds of tasks, such as regression, classification, or even more complex objectives.
In regression tasks, where the output is a continuous number, common choices include Mean Squared Error (MSE) and Mean Absolute Error (MAE). MSE squares the difference between prediction and true value, making larger errors count more heavily. MAE, on the other hand, takes the absolute difference, treating all errors equally. These two give slightly different behaviors—MSE tends to penalize large mistakes more, making it sensitive to outliers.
For classification tasks, where the output is a category, the loss functions are a bit different. One of the most widely used is cross-entropy loss, which measures the distance between two probability distributions: the model’s predicted probabilities and the actual one-hot encoded labels. This encourages the model to output high confidence for the correct class and low confidence for the wrong ones.
There are even more specialized losses for particular situations. Hinge loss, for example, is commonly used for support vector machines. Huber loss is designed for regression tasks where you want to reduce sensitivity to outliers but still penalize larger mistakes more than smaller ones.
The choice of loss function can significantly affect how a model behaves during training. It shapes the landscape that the optimization algorithm navigates. A poorly chosen loss function might make learning very slow, or worse, cause the model to settle on bad solutions.
Every time the model makes a prediction, the loss function evaluates that prediction. Then, an optimization algorithm, most often some variant of gradient descent, updates the model's parameters to reduce the loss. This cycle repeats for many iterations, gradually improving the model's predictions.
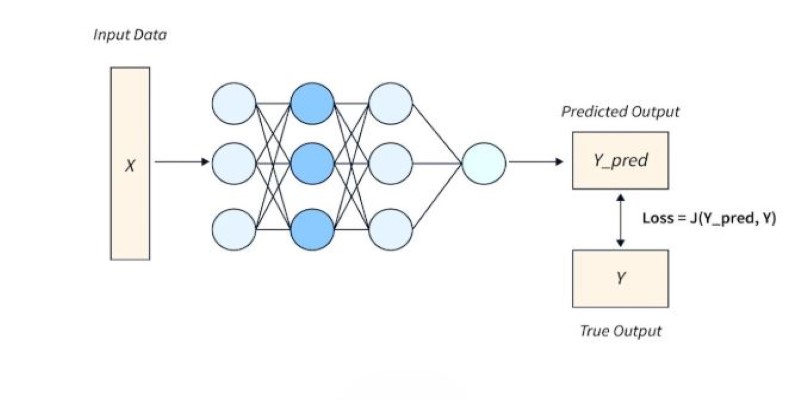
The loss function provides the gradients—slopes that tell the optimizer which direction to adjust each parameter. If the loss function is not smooth or differentiable, it can make optimization harder. That’s why many popular loss functions are designed to be easy to differentiate.
Training a model can sometimes be compared to finding the lowest point in a valley. The shape of the valley is determined by the loss function. A well-designed loss function creates a valley with a clear minimum that the optimizer can find. A poorly designed loss might create lots of bumps and flat areas, making it harder for the optimizer to reach the best point.
Regularization techniques can also be incorporated into the loss function to help prevent overfitting. Terms like L1 or L2 penalties can be added to discourage the model from learning overly complex or extreme parameter values.
Picking the right loss function is one of the first steps when building a model. The type of problem you’re solving usually dictates the choice. For example, for predicting continuous values, MSE or MAE are natural choices. For binary classification, binary cross-entropy fits well. For multi-class classification, categorical cross-entropy is preferred.
Sometimes the choice isn’t obvious. If your data has many outliers, MSE might make your model overly sensitive to those, so MAE or Huber loss could work better. For imbalanced classification tasks, you might need to modify the standard loss to penalize mistakes in the minority class more heavily.
Experimentation can help when in doubt. Trying a few different loss functions and evaluating how the model performs on a validation set often gives insight into which one suits the problem better.
Custom loss functions can also be written when the standard ones don’t capture what you care about. For example, in recommendation systems, the loss function might combine ranking quality and prediction accuracy. In such cases, domain knowledge often guides how the loss function is designed.
Loss functions may not get as much attention as flashy algorithms or intricate models, but they’re at the heart of every machine learning system. They define what it means for a prediction to be “bad” and provide the feedback needed to improve. From regression to classification, standard or custom-made, loss functions shape the learning process and influence how well a model can generalize. By understanding how they work and choosing one that aligns with the problem at hand, you give your model the right kind of guidance as it learns from data. Every model is only as good as the objective it’s trying to optimize, and the loss function defines that objective clearly and consistently.
Advertisement
Confused between lazy learning and eager learning? Explore the differences between these two approaches and discover when to use each for optimal performance in machine learning tasks

How to implement Policy Gradient with PyTorch to train intelligent agents using direct feedback from rewards. A clear and simple guide to mastering this reinforcement learning method

Learn how to boost sales with Generative AI. Learn tools, training, and strategies to personalize outreach and close deals faster

Explore seven advanced Claude Sonnet strategies to simplify operations, boost efficiency, and scale your business in 2025.

Can ChatGPT be used as a proofreader for your daily writing tasks? This guide explores its strengths, accuracy, and how it compares to traditional AI grammar checker tools

GenAI helps Telco B2B sales teams cut admin work, boost productivity, personalize outreach, and close more deals with automation

Explore how generative AI in financial services and other sectors drives growth, efficiency, and smarter decisions worldwide

Looking to build practical AI that runs at the edge? The AMD Pervasive AI Developer Contest gives you the tools, platforms, and visibility to make it happen—with real-world impact

Discover the top 9 open source graph databases ideal for developers in 2025. Learn how these tools can help with graph data storage, querying, and scalable performance
Explore Airflow data intervals, scheduling, catch-up, and backfilling to design reliable workflows and optimize task execution

Discover how AI reshapes contact centers through automation, omnichannel support, and real-time analytics for better experiences

How to write a custom loss function in TensorFlow with this clear, step-by-step guide. Perfect for beginners who want to create tailored loss functions for their models