Advertisement
Machines have come a long way in processing human language, and BERT (Bidirectional Encoder Representations from Transformers) is a big reason for that progress. Developed by Google, BERT looks at words in both directions — left to right and right to left — to understand meaning more accurately. Unlike older models that could only process one way, BERT’s bidirectional approach allows it to pick up subtle context in sentences. For beginners interested in artificial intelligence and natural language processing, understanding how the BERT architecture works opens the door to seeing how computers interpret language more naturally than ever.
Older models processed text in a single direction. They would read sentences from start to end or end to start, which limited their understanding. Words often depend on context from both before and after, and without seeing everything, these models struggled. Take the word “bank” in “I sat by the river bank.” Only by looking at the entire sentence can you tell that “bank” means the side of a river, not a financial institution.
BERT solved this by processing sentences in both directions at once. This is called bidirectional context, and it helps the model understand what a word means based on everything around it. This ability to capture meaning more precisely made BERT the basis for many natural language processing applications such as search engines, question answering systems, and text summarization.
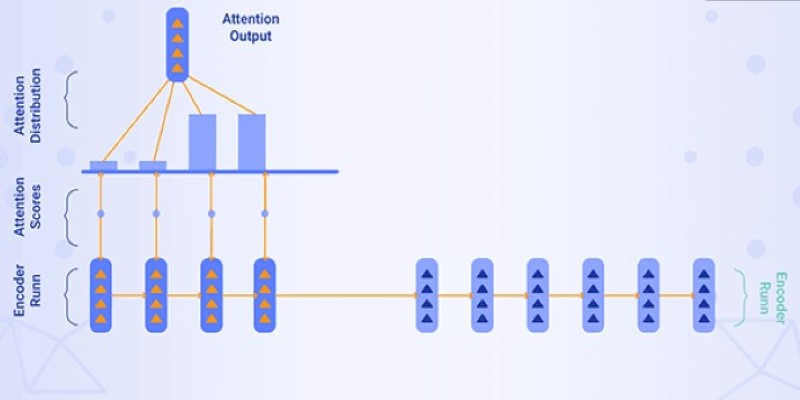
The key to BERT’s success lies in the Transformer architecture. Transformers allow the model to focus on all parts of a sentence at the same time, rather than working word by word. This is made possible by an attention mechanism that determines which words are more relevant to others. By paying attention to relationships between all words, the Transformer makes it possible for BERT to understand how even distant words in a sentence affect each other.
At its core, BERT is a stack of Transformer encoder layers. The standard BERT model has 12 layers, while a larger version has 24. Each layer has two main parts: self-attention and a feed-forward network. Self-attention allows the model to figure out how much importance to assign to each word relative to others. For example, in “The animal didn’t cross the street because it was too tired,” the word “it” refers to “the animal,” and self-attention helps BERT make that connection. This ability to pick up on long-distance relationships sets it apart from earlier models.
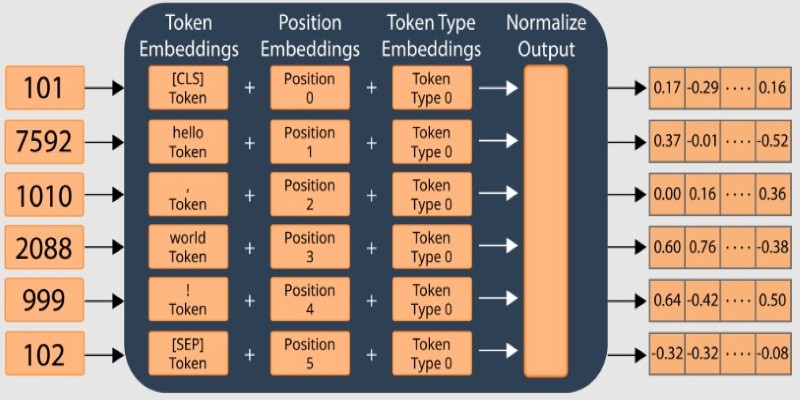
Before text enters the model, it is broken into tokens using WordPiece tokenization. Tokens can be full words or smaller pieces. For example, “playing” might be split into “play” and “##ing.” This allows the model to handle uncommon or unknown words by working with smaller pieces it already knows.
BERT also uses special tokens in its input. Every sequence starts with a [CLS] token, which is used for classification tasks. If two sentences are being processed together, a [SEP] token separates them. These tokens help BERT figure out the task at hand, whether it’s sentence comparison, classification, or something else.
BERT’s effectiveness comes from how it learns. It goes through a pretraining phase where it reads huge amounts of text, like books and articles, without labels. This helps it learn general language patterns. Pretraining involves two tasks: masked language modeling and next sentence prediction.
In masked language modeling, some words are replaced with a [MASK] token, and the model predicts what the missing word should be by looking at the surrounding words. This teaches BERT to use context from both directions to figure out meaning.
In next sentence prediction, the model is given two sentences and must decide if the second sentence logically follows the first. This helps BERT learn how sentences relate to each other, which is useful for tasks like question answering or summarization.
Once pretraining is complete, BERT is fine-tuned for specific tasks. Fine-tuning is much quicker and needs less data because the model already understands language. For example, to use BERT for spam detection, you only need to train it on a labeled dataset of emails. This flexibility and efficiency have made BERT a popular choice for many practical applications.
BERT was released in 2018, but its influence is still strong today. Many newer models are based on the same ideas, improving on them with more layers, more parameters, or better training methods. But the core concept — using bidirectional Transformers — remains central to modern natural language processing.
BERT made it easier for developers and researchers to achieve high performance on a wide variety of language tasks without needing massive amounts of task-specific data. Even though larger and more advanced models have appeared since, BERT’s balance of efficiency and effectiveness means it’s still widely used in search engines, chatbots, and text analysis tools.
Understanding BERT architecture helps you see how far natural language processing has come and gives you a foundation for exploring newer models. It’s a clear example of how combining attention mechanisms, bidirectional context, and smart training objectives can make machines much better at handling human language.
BERT architecture shows how machines can better understand the words we use by looking at the full context around them. It brought a new way of thinking to natural language processing by using bidirectional Transformers and a clever pretraining method that teaches models about language before applying them to specific tasks. With its layers of self-attention and flexible fine-tuning process, BERT remains an important tool for anyone working with text data. Learning its basic structure is a good step for anyone curious about how artificial intelligence models process and understand language today.
Advertisement

Discover the top eight ChatGPT prompts to create stunning social media graphics and boost your brand's visual identity.

Tech giants respond to state-level AI policies, advocating for unified federal rules to guide responsible AI use.

How Locally Linear Embedding helps simplify high-dimensional data by preserving local structure and revealing hidden patterns without forcing assumptions
Explore Airflow data intervals, scheduling, catch-up, and backfilling to design reliable workflows and optimize task execution

How MetaGPT is reshaping AI-powered web development by simulating a full virtual software team, cutting time and effort while improving output quality

Discover powerful yet lesser-known ChatGPT prompts and commands that top professionals use to save time, boost productivity, and deliver expert results
How far can AI go when it comes to problem-solving? Google's new Gemini model steps into the spotlight to handle complex tasks with surprising nuance and range
What loss functions are, why they matter, and how they guide machine learning models to make better predictions. A beginner-friendly explanation with examples and insights

A Nvidia AI-powered humanoid robot is now serving coffee to visitors in Las Vegas, blending advanced robotics with natural human interaction in a café setting
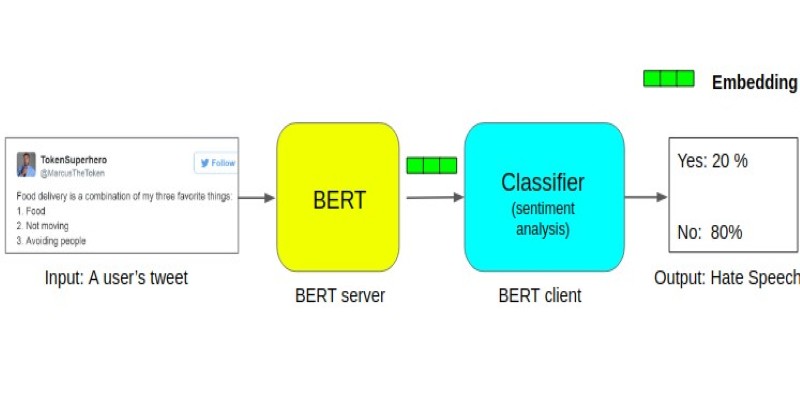
Learn about the BERT architecture explained for beginners in clear terms. Understand how it works, from tokens and layers to pretraining and fine-tuning, and why it remains so widely used in natural language processing
How to create RDD in Apache Spark using PySpark with clear, step-by-step instructions. This guide explains different methods to build RDDs and process distributed data efficiently

Explore the key features, benefits, and top applications of OpenAI's GPT-4.1 in this essential 2025 guide for businesses.