Advertisement
The way systems generate text is changing—and not in subtle ways. In recent years, what used to be a linear, step-by-step generation has moved toward something smarter, quicker, and more responsive. One approach leading this shift is Dynamic Speculation, a method that speeds up assisted generation while maintaining quality and structure. It isn't about shortcuts; it's about letting models work more efficiently behind the scenes so responses feel quicker, tighter, and closer to what's expected.
Let’s walk through how Dynamic Speculation actually works, why it matters, and what makes it so effective in speeding up assisted text generation.
At its core, Dynamic Speculation is a strategy for guessing ahead. It allows a system to predict more than one possible next token (or word piece) and begin working on them in parallel instead of waiting for confirmation of each one before moving forward.
Think of it like walking down a path and sending out scouts in multiple directions instead of waiting at each fork until you're certain which way to go. The scouts give you a head start—if you're right about the next few steps, you move forward much faster. If not, you backtrack slightly and adjust. But even with occasional missteps, the overall time saved outweighs the corrections.
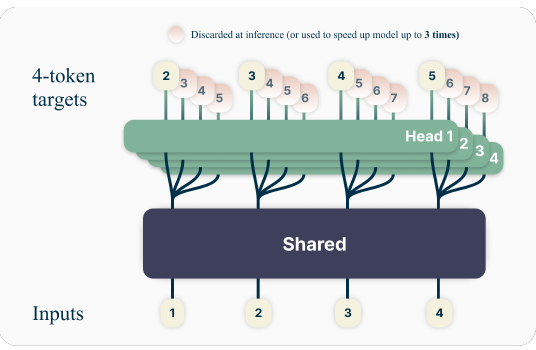
Traditional token generation processes are slow because they're serial. One token gets generated, then another, and then the next. But in dynamic speculation, multiple tokens are generated ahead of time as “drafts.” The system then evaluates these drafts to see how far it can commit. The key difference is in how much work is done in advance and how the system makes use of those predictions without waiting idly between steps.
The reason this approach feels faster isn't because the machine is doing less work—it’s because it's working smarter.
During generation, multiple future tokens are predicted by a smaller, faster model. These predictions are temporary placeholders, referred to as speculative tokens. While the primary model—the one responsible for the final output—is busy computing, the draft model works ahead, laying down options.
Once the primary model finishes processing the confirmed input, it checks the speculative tokens to see how many of them it agrees with. If the predictions match what the full model would have produced anyway, those tokens get accepted instantly. If they don’t match, the generation rolls back to the last correct token, and the rest gets recalculated.
This back-and-forth might sound inefficient, but in practice, the agreement rate between draft and final models is surprisingly high. That means most of the speculative work doesn't go to waste—it accelerates the process meaningfully.
Without speculation, each token waits for the last one to finish before it begins. This bottleneck adds latency. Speculative decoding shortens the gap. Drafting multiple tokens in advance keeps the pipeline full and responsive, which results in a smoother experience for the user.
So, while the model still has to do the hard work of confirming each token, the time spent doing nothing is almost eliminated.
One common question is what happens when the speculative predictions are wrong. That’s where the “dynamic” part comes in.
Instead of hardcoding how many speculative tokens to generate or accept, the system adapts. If a draft model keeps producing tokens the final model disagrees with, the speculative window shortens automatically. If agreement is high, it expands. This keeps efficiency up without sacrificing quality.
Whenever disagreement happens, the model simply drops the incorrect tokens and recalculates from the last trusted point. It doesn't mean the whole process needs to restart—just that it needs to pick up from the last accurate checkpoint. These rollbacks are fast because they involve reusing cached computations wherever possible.
And because disagreements are relatively rare with well-tuned draft models, the number of rollbacks stays low. It’s a practical tradeoff: a few extra calculations in exchange for a big gain in speed.
The speculation window—the number of tokens guessed ahead—doesn't stay fixed. It adjusts in real time based on performance. This helps avoid wasting computing power on long speculative branches that are likely to be wrong. The system learns how far it can stretch without tripping up. So, it's not just fast—it’s self-aware in how it stays fast.
Let’s break down how this works in a simplified step-by-step format.
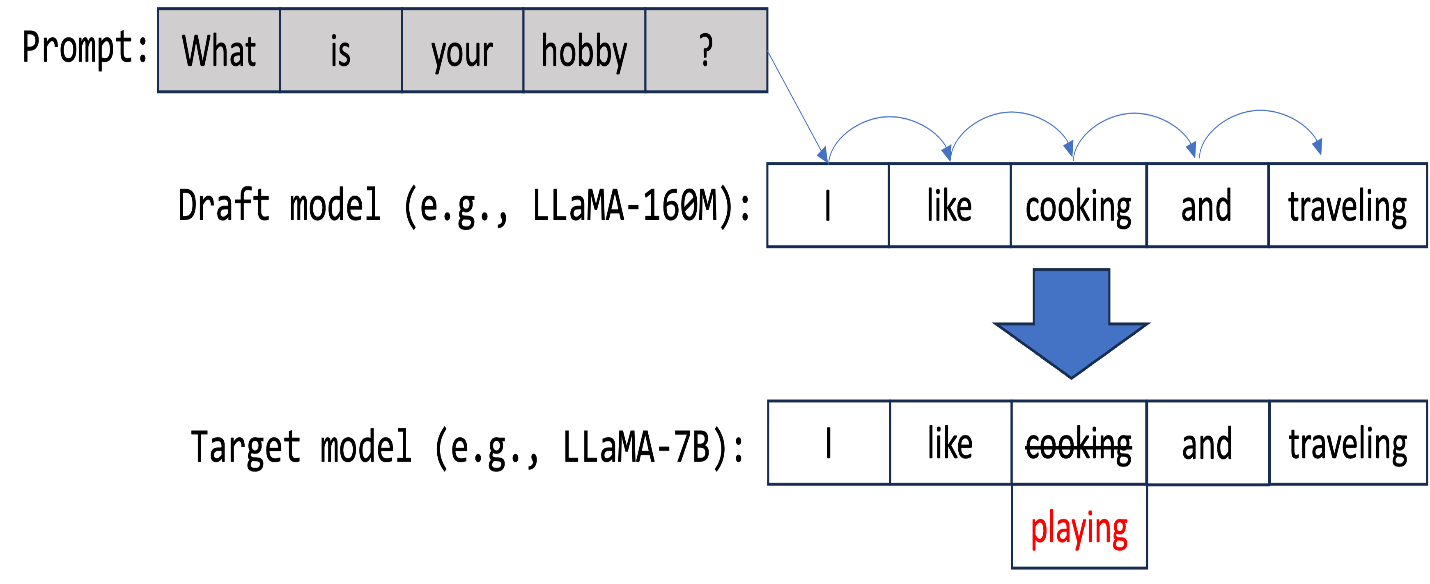
The user provides an input prompt. This is the starting point. The primary model begins processing it.
While the primary model is still working, a smaller draft model predicts the next few tokens that might follow the current input.
Once the primary model finishes its current step, it compares the speculative tokens with what it would have generated on its own.
The system tracks how often the draft tokens are correct. If accuracy is high, the number of speculative tokens increases. If not, it decreases.
This process continues until the model finishes generating the full response.
Dynamic Speculation helps models generate text faster by making smart predictions in parallel and adjusting on the fly. It doesn’t skip steps—it just rearranges them more efficiently. With its ability to reduce response time without compromising accuracy, it’s quickly becoming a go-to approach for real-time AI systems. Whether it's used in chats, writing assistants, or predictive typing, the result is the same: quicker, cleaner outputs that feel natural, even when there's a lot going on under the hood.
Advertisement

A Nvidia AI-powered humanoid robot is now serving coffee to visitors in Las Vegas, blending advanced robotics with natural human interaction in a café setting

Understand what machine learning (ML) is, its major types, why it is so important, how it works, and more in detail here

How the latest PayPal AI features are changing the way people handle online payments. From smart assistants to real-time fraud detection, PayPal is using AI to simplify and secure digital transactions

Explore seven advanced Claude Sonnet strategies to simplify operations, boost efficiency, and scale your business in 2025.

Discover the best Business Intelligence tools to use in 2025 for smarter insights and faster decision-making. Explore features, ease of use, and real-time data solutions

How AI in software development is transforming how developers write, test, and maintain code. Learn how artificial intelligence improves efficiency, automates repetitive tasks, and enhances software quality across every stage of the development process

How a groundbreaking AI model for robotic arms is transforming automation with smarter, more adaptive performance across industries

Tech giants respond to state-level AI policies, advocating for unified federal rules to guide responsible AI use.

Explore the real-world differences between Claude AI and ChatGPT. This comparison breaks down how these tools work, what sets them apart, and which one is right for your tasks

Discover the top 9 open source graph databases ideal for developers in 2025. Learn how these tools can help with graph data storage, querying, and scalable performance

How to implement Policy Gradient with PyTorch to train intelligent agents using direct feedback from rewards. A clear and simple guide to mastering this reinforcement learning method

How Locally Linear Embedding helps simplify high-dimensional data by preserving local structure and revealing hidden patterns without forcing assumptions